1 Modeling the Brain: Translating Neurons into Networks
In Fig. 1 each neuron, shown in a different color, represents a biological neuron that could receive distinct sensory inputs from different sources, such as the nose, eye, and tongue. Each neuron processes its incoming signals through its dendrites, integrates them in the soma (cell body), and transmits its output through the axon to the next neuron across a synapse. Together, this network of interconnected neurons can combine multisensory information to make an integrated decision, such as identifying what type of food is being perceived based on smell, sight, and taste. This biological mechanism of signal integration and communication serves as the conceptual foundation for artificial neural networks.
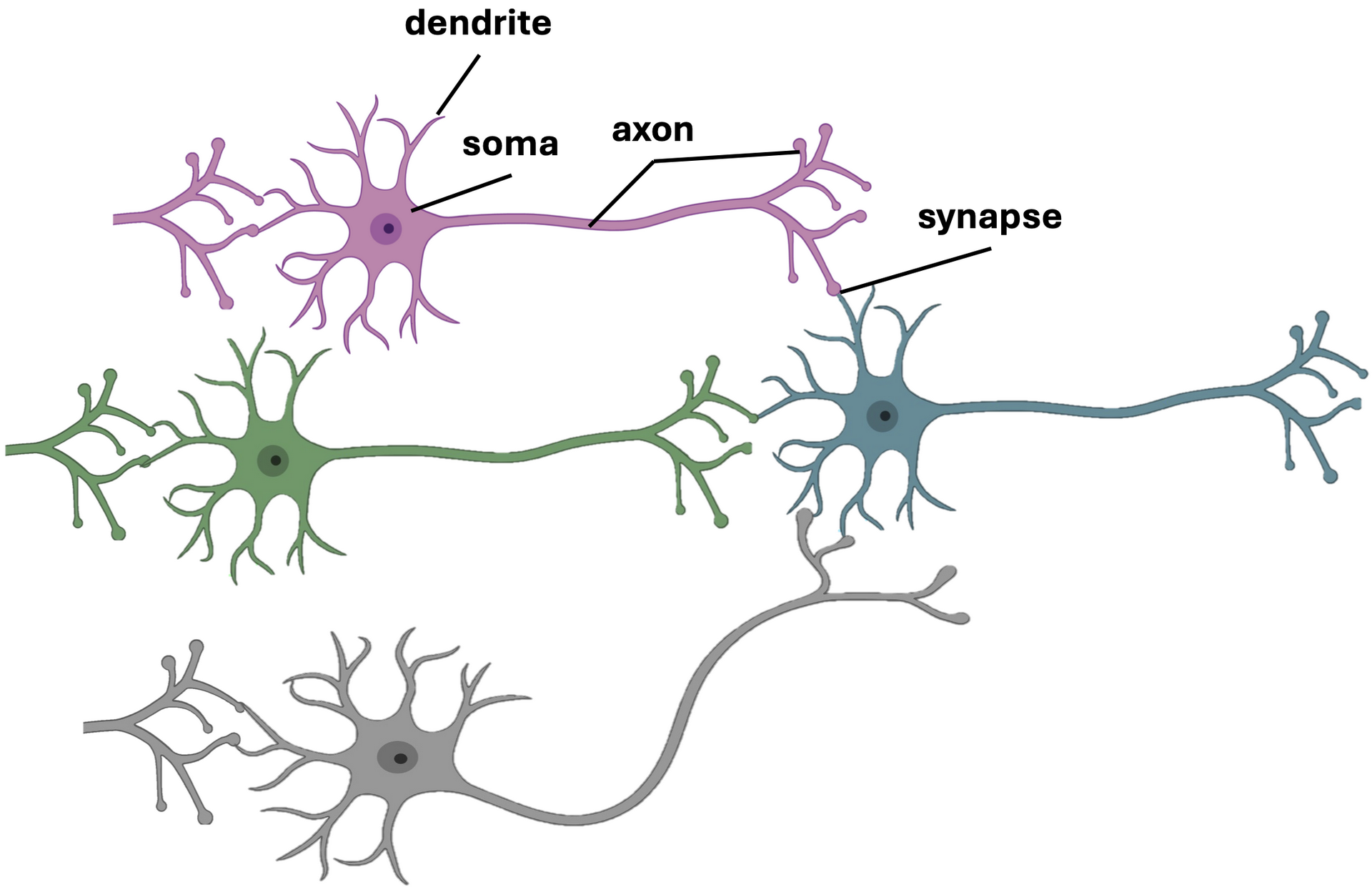 Fig. 1 Structure and connectivity of biological neurons. Schematic illustration showing key components of neurons, including dendrites, soma, axon, and synapse. Neurons receive input signals through dendrites, integrate them in the soma, and transmit electrical impulses along the axon to other neurons via synapses, forming complex communication networks in the brain.
Fig. 1 Structure and connectivity of biological neurons. Schematic illustration showing key components of neurons, including dendrites, soma, axon, and synapse. Neurons receive input signals through dendrites, integrate them in the soma, and transmit electrical impulses along the axon to other neurons via synapses, forming complex communication networks in the brain.
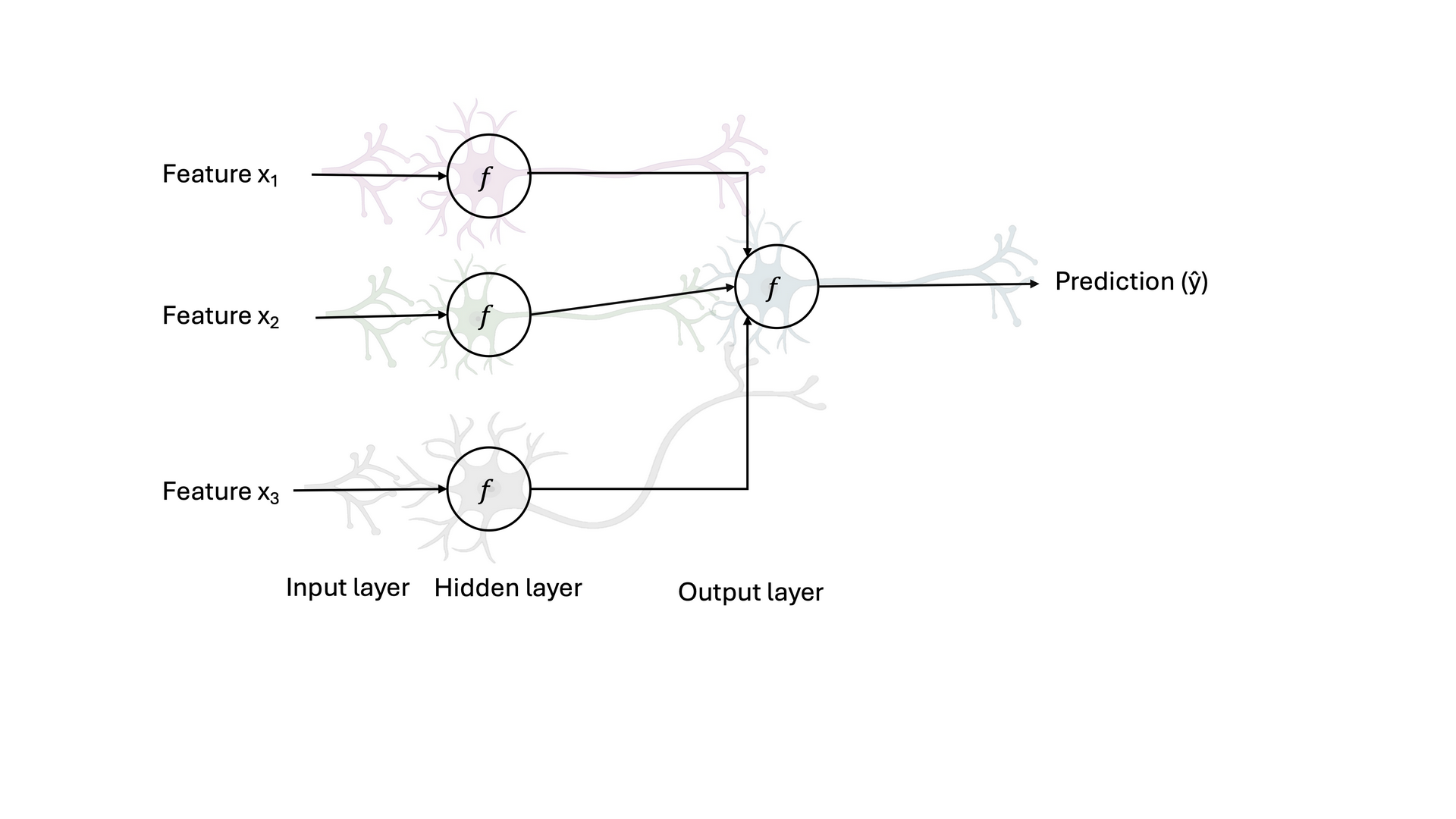
Fig. 2 illustrates how this biological inspiration translates into the structure of an artificial neural network (ANN). Each circle labeled \(f\) represents an artificial neuron or activation function. Features \( x_1, x_2\) and \(x_3 \) correspond to input signals, analogous to sensory data, which are processed in the input layer and passed to a hidden layer where nonlinear transformations are applied. These transformed signals are then combined to produce a prediction (ŷ) in the output layer. The weighted connections between layers mimic how electrical impulses travel between neurons, enabling the ANN to learn complex relationships from input data and make intelligent predictions, much like the brain integrates sensory information to recognize and classify objects.
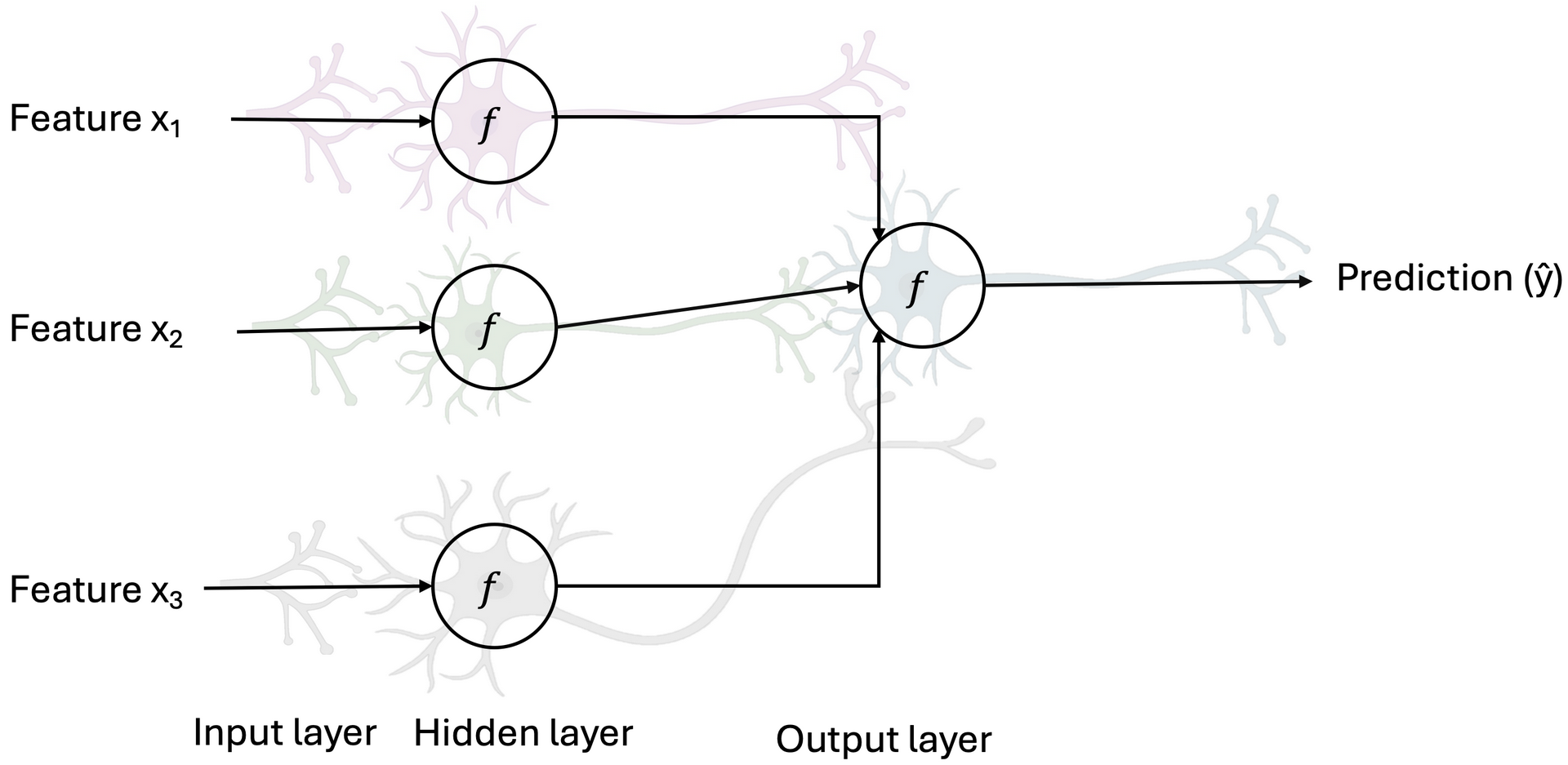 Fig. 2 Architecture of an artificial neural network (ANN) inspired by biological neurons. Diagram showing how input features \( x_1, x_2\) and \(x_3 \) are processed through interconnected layers of artificial neurons (f) in a neural network. The input layer passes signals to a hidden layer that performs nonlinear transformations, leading to an output neuron that produces the prediction (ŷ), analogous to signal transmission and integration in biological neural systems.
Fig. 2 Architecture of an artificial neural network (ANN) inspired by biological neurons. Diagram showing how input features \( x_1, x_2\) and \(x_3 \) are processed through interconnected layers of artificial neurons (f) in a neural network. The input layer passes signals to a hidden layer that performs nonlinear transformations, leading to an output neuron that produces the prediction (ŷ), analogous to signal transmission and integration in biological neural systems.
2 Fundamentals of Scalar and Vector Functions
2.1 Scalar Function, Scalar Field, Vector Function, and Vector Field
A scalar function (aka scalar-valued function) like \( f(x,y) = x^2 + y^2 \) is a map \( f: \mathbb{R}^n \to \mathbb{R} \) that assigns a single real number (a scalar) to each point in its domain. A scalar field is a physical or geometric interpretation of a scalar function; it assigns a scalar value to every point in space (or spacetime).
A vector function (aka vector-valued function) is a map \( \mathbf{F}: \mathbb{R}^n \to \mathbb{R}^m \) like \(\mathbf{F}(x,y) = \begin{bmatrix} x^2 + y^2 & \sin(xy) \end{bmatrix}\) that assigns a vector in \( \mathbb{R}^m \) to each point in \( \mathbb{R}^n \). The input of a vector-valued function could be a scalar or a vector (that is, the dimension of the domain could be 1 or greater than 1); the dimension of the function’s domain has no relation to the dimension of its range. A vector field is a vector function \( \mathbf{F}: \mathbb{R}^n \to \mathbb{R}^n \) that assigns a vector in \( \mathbb{R}^n \) to each point in space. In some contexts, the codomain could be \( \mathbb{R}^m \), but vector fields in \( \mathbb{R}^n \) typically have codomain \( \mathbb{R}^n \).
A linear vector function can be expressed in terms of matrices. The linear case arises often in multiple regression analysis, where the \( 1 \times m \) vector \( \hat{\mathbf{y}} \) of predicted values of a dependent variable \( \mathbf{y} \) is expressed linearly in terms of an \( n \times 1 \) vector \( \mathbf{w} \) of estimated values of model parameters (\( \hat{\mathbf{y}}: \mathbb{R}^n \to \mathbb{R}^m \)):
\[\hat{\mathbf{y}}(\mathbf{w}) = \begin{bmatrix} \mathbf{w} \cdot X_1 & \dots & \mathbf{w} \cdot X_m \end{bmatrix} = \mathbf{w}^T X,\]
in which \( \mathbf{X} \) is an \( n \times m \) matrix of fixed (empirically based) numbers, \( \mathbf{X}_i \) is a column vector, and \( \cdot \) is the dot product.
Many vector-valued functions, like scalar-valued functions, can be differentiated by simply differentiating the components. In Cartesian coordinates, if \( \mathbf{F} = (F_1, F_2, \dots, F_m) \), where each \( F_i: \mathbb{R}^n \to \mathbb{R} \) (\( \mathbf{F}: \mathbb{R}^n \to \mathbb{R}^m \)) is a scalar function, the differential is represented by the Jacobian matrix:
\[d\mathbf{F}_p = \begin{bmatrix}\frac{\partial F_1}{\partial x_1} & \dots & \frac{\partial F_1}{\partial x_n} \\\vdots & \ddots & \vdots \\\frac{\partial F_m}{\partial x_1} & \dots & \frac{\partial F_m}{\partial x_n}\end{bmatrix} = \begin{bmatrix} \nabla F_1 \\ \vdots \\ \nabla F_m \end{bmatrix},\]
where the partial derivative of a vector function \( \mathbf{F} \) with respect to a scalar variable \( x_j \) is defined as\[\frac{\partial \mathbf{F}}{\partial x_j} = \sum_{i=1}^m \frac{\partial F_i}{\partial x_j} \mathbf{e}_i.\]
The vectors \( \mathbf{e}_1, \mathbf{e}_2, \mathbf{e}_3 \) form an orthonormal basis fixed (like Cartesian coordinate system) in the reference frame in which the derivative is being taken.
2.2 Spaces and Coordinate Systems
When working with scalar-valued or vector-valued functions, it is essential to recognize that these functions can exist in a variety of mathematical spaces, each equipped with its own structure and compatible coordinate systems. For instance, functions may be defined on Euclidean spaces such as \( \mathbb{R}^2 \) or \( \mathbb{R}^3 \), on curved surfaces like spheres or manifolds, or even on abstract vector spaces where distance and direction are generalized. The choice of coordinate system, Cartesian, polar, cylindrical, or spherical, must be compatible with the geometry of the space and the behavior of the function. Scalar fields, which assign a single value to every point, and vector fields, which assign a vector to each point, both depend on how these coordinates are defined and transformed. For example, gradients, divergences, and curls take different forms under different coordinate systems, even though the underlying geometric quantities remain invariant. Thus, a clear understanding of the underlying space and its coordinate representation is fundamental for expressing, interpreting, and manipulating scalar and vector functions correctly in both mathematical and physical contexts.
2.3 Level Set, Tangent Space, and Tangent Vector
Level set (or contour) at point \( \mathbf{x} \) is the set of all points in the scalar field where the function has the same constant value as \( f(\mathbf{x}) \). For example, on a topographic map (like mountains from above), these are the contour lines connecting points of equal elevation. \( \nabla f(\mathbf{x}) \) is sometimes called a tangent vector at \( \mathbf{x} \), while ``Tangent'' here does not mean tangent to \( f \) or even its level set at point \( \mathbf{x} \). This is a common point of confusion. On the contrary, the gradient vector at a point is a normal (orthogonal) to the level set, passing through that point, and every vector tangent to it. In fact, in some geometric contexts, especially in differential geometry, every vector attached to a point, even a normal vector, formally lives in the tangent space at that point. In a Euclidean space, the tangent space at a point \( \mathbf{x} \in \mathbb{R}^n \), denoted by \( T_{\mathbf{x}} \mathbb{R}^n \), is simply the space itself. For example, in 3D Euclidean space (\( \mathbb{R}^3 \)), the tangent space at any point \( (x, y, z) \) is just another copy of \( \mathbb{R}^3 \). This might seem trivial, but it becomes crucial when you consider more complex curved spaces (manifolds) where the tangent space at each point can be different.
2.4 Directional Derivative
The directional derivative of a scalar field \( f: \mathbb{R}^n \to \mathbb{R} \) in Euclidean space at a point \( \mathbf{x} \in \mathbb{R}^n \) in the direction of a vector \( \mathbf{v} \in \mathbb{R}^n \) is a measure of the rate of change of \( f \) along the direction \( \mathbf{v} \) and is defined as:
\[D_{\mathbf{v}} f(\mathbf{x}) = \lim_{h \to 0} \frac{f(\mathbf{x} + h \mathbf{v}) - f(\mathbf{x})}{h \|\mathbf{v}\|},\]
where:
- \( \mathbf{v} \in \mathbb{R}^n \) is an arbitrary nonzero vector and a tangent vector of the tangent space at \( \mathbf{x} \). To adjust a formula for the directional derivative to work for any vector, one must divide the expression by the magnitude of the vector, \( \|\mathbf{v}\| \). If \( \mathbf{v} \) is already a unit vector (\( \|\mathbf{v}\| = 1 \)), \( D_{\mathbf{v}} f(\mathbf{x}) \) gives the rate of change per unit distance in that direction. That’s why many mathematical texts assume that the directional vector is normalized, denoted by \( \hat{\mathbf{v}} \).
- \( h \in \mathbb{R} \) is a scalar parameter.
This definition is coordinate-free because it depends only on the Euclidean structure of \( \mathbb{R}^n \) (points, vectors, and the ability to add vectors and scale them) and the values of \( f \), without reference to any specific coordinate system like Cartesian or polar coordinates.
The directional derivative \( D_{\mathbf{v}} f(\mathbf{x}) \) may exist for a specific direction \( \mathbf{v} \) even if \( f \) is not differentiable at \( \mathbf{x} \). Differentiability of \( f \) at \( \mathbf{x} \) requires that the directional derivative exists for all directions \( \mathbf{v} \) and that the map \( \mathbf{v} \mapsto D_{\mathbf{v}} f(\mathbf{x}) \) is linear (i.e., \( D_{\mathbf{v}} f(\mathbf{x}) = \nabla f(\mathbf{x}) \cdot \mathbf{v} \)). If \( f \) is not differentiable, the directional derivative may exist in some directions but not others, or it may exist in all directions but fail to be linear. If \( f \) is differentiable at \( \mathbf{x} \), the directional derivative in any direction \( \mathbf{v} \) can be computed using the gradient \( \nabla f(\mathbf{x}) \), which exists and is a vector in \( \mathbb{R}^n \). The gradient is defined such that:
\[D_{\mathbf{v}} f(\mathbf{x}) = \nabla f(\mathbf{x}) \cdot \mathbf{v},\]
where \( \cdot \) is the Euclidean dot product. This follows because differentiability implies that the function’s rate of change is linear in the direction \( \mathbf{v} \), and the gradient \( \nabla f(\mathbf{x}) \) is the unique vector satisfying this for all \( \mathbf{v} \). In this case, the directional derivative is a linear functional on the tangent space, and its value depends smoothly on the direction. Directional derivative may also be denoted by \( D_{\mathbf{v}} f(\mathbf{x}) = \frac{\partial f(\mathbf{x})}{\partial \mathbf{v}} \).
Del, or nabla, is an operator used in mathematics (particularly in vector calculus) as a vector differential operator, usually represented by \( \nabla \). As a vector operator, it can act on scalar and vector fields in three different ways, giving rise to three different differential operations: (1) it can act on scalar fields (or vector fields component-wise) by a formal scalar multiplication (\( \text{grad} f = \nabla f \)), to give a vector field called the gradient, (2) it can act on vector fields by a formal dot product (\( \text{div} \mathbf{v} = \nabla \cdot \mathbf{v} \)) to give a scalar field called the divergence, (3) and lastly, it can act on vector fields by a formal cross product (\( \text{curl} \mathbf{v} = \nabla \times \mathbf{v} \)) to give a vector field called the curl. In the Cartesian coordinate system \( \mathbb{R}^n \) with coordinates \( (x_1, \dots, x_n) \) and standard basis \( \{\mathbf{e}_1, \dots, \mathbf{e}_n\} \), del is a vector operator whose \( x_1, \dots, x_n \) components are the partial derivative operators \( \frac{\partial}{\partial x_1}, \dots, \frac{\partial}{\partial x_n} \); that is,
\[\nabla = \sum_{i=1}^n \mathbf{e}_i \frac{\partial}{\partial x_i} = \left( \frac{\partial}{\partial x_1}, \dots, \frac{\partial}{\partial x_n} \right),\]
where the expression in parentheses is a row vector. Note that \( \mathbf{v} \cdot \nabla \) is also an operator that maps scalars to scalars. It can be extended to act on a vector field by applying the operator component-wise to each component of the vector.
2.5 Gradient
In Euclidean space \( \mathbb{R}^n \), equipped with the standard dot product, the gradient of a differentiable scalar field \( f: \mathbb{R}^n \to \mathbb{R} \) at a point \( \mathbf{x} \in \mathbb{R}^n \) is the unique vector \( \nabla f(\mathbf{x}) \in \mathbb{R}^n \) (a vector field) such that for every vector \( \mathbf{v} \in \mathbb{R}^n \) (a tangent vector at \( \mathbf{x} \)), the directional derivative of \( f \) at \( \mathbf{x} \) in the direction \( \mathbf{v} \) satisfies:
\[D_{\mathbf{v}} f(\mathbf{x}) = \nabla f(\mathbf{x}) \cdot \mathbf{v},\]
where:
- \( \cdot \) denotes the Euclidean dot product in \( \mathbb{R}^n \).
- \( \mathbb{R}^n \) is both the space and its tangent space at \( \mathbf{x} \), so \( \mathbf{v} \) and \( \nabla f(\mathbf{x}) \) are vectors in \( \mathbb{R}^n \).
This definition is coordinate-free because it relies only on: (i) the Euclidean vector space structure (addition, scaling, and the dot product), and (ii) the values of \( f \) and the directional derivatives, without reference to a specific coordinate system (e.g., Cartesian, polar). In the \( n \)-dimensional Cartesian coordinate system with a Euclidean metric, the gradient, if it exists at \( \mathbf{x} \), is given by:
\[\nabla f(\mathbf{x}) = \left( \frac{\partial f}{\partial x_1}(\mathbf{x}), \frac{\partial f}{\partial x_2}(\mathbf{x}), \dots, \frac{\partial f}{\partial x_n}(\mathbf{x}) \right).\]
The gradient \( \nabla f(\mathbf{x}) \) points in the direction in which \( f \) increases (positive values) most rapidly from \( \mathbf{x} \), while its magnitude, \( \|\nabla f(\mathbf{x})\| \), gives the rate of change of \( f \) in the direction of steepest ascent. The gradient thus plays a fundamental role in optimization theory, where it is used to minimize a function by gradient descent. The directional derivative, \( D_{\mathbf{v}} f(\mathbf{x}) = \nabla f(\mathbf{x}) \cdot \mathbf{v} = \|\nabla f(\mathbf{x})\| \|\mathbf{v}\| \cos \theta \), is equal to the maximum value \( \|\nabla f(\mathbf{x})\| \) when \( \mathbf{v} \) (normalized) is aligned with \( \nabla f(\mathbf{x}) \).
3 Mathematical Representation of Model Parameters and Data Structure
This schematic below (Fig. 3) shows how input features and parameters interact in supervised learning. The blue-shaded cells represent model parameters, the weights (\(w_i\)) and bias (\(b\)), while the orange-shaded cells denote the predicted outputs (\(\hat{y}^i\)). Each column corresponds to a training example, and each row corresponds to a feature, illustrating how examples and their labels are organized within the data matrix used for learning.

Fig. 3 Tabular representation of input data, parameters, and predictions.
\( X = \begin{bmatrix} \mathbf{x}^{(1)} & \cdots & \mathbf{x}^{(m)} \end{bmatrix}_{n \times m} \)
\(\mathbf{y} = \begin{bmatrix} y^{(1)} & \cdots & y^{(m)} \end{bmatrix}_{1 \times m}\)
\(\mathbf{w} = \begin{bmatrix} w_1 & \cdots & w_m \end{bmatrix}_{1 \times m}\)
\(\hat{\mathbf{y}} = \mathbf{F}(\mathbf{w}, b) = \begin{bmatrix} \hat{y}^{(1)} = F_1 (\mathbf{w}, b) & \cdots & \hat{y}^{(m)} = F_m (\mathbf{w}, b) \end{bmatrix}_{1 \times m}\)
\(\mathbf{L} = \mathbf{G}(\mathbf{w}, b) = \begin{bmatrix} L^{(1)} = G_1 (\mathbf{w}, b) & \cdots & L^{(m)} = G_m (\mathbf{w}, b) \end{bmatrix}_{1 \times m}\)
\(C = H(\mathbf{w}, b)\)
where:
- \( X \) is the table of examples (a matrix),
- \( \mathbf{x}^{(i)} \) is the i-th example (a scalar column vector),
- \( \mathbf{x}_j \) is the j-th feature (a scalar row vector),
- \( \mathbf{y} \) is the labels (a scalar row vector),
- \( y^{(i)} \) is the i-th example’s label (a scalar)
- \( \mathbf{w} \) is the coeffects (a scalar column vector),
- \( w_j \) is the j-th coefficient (a scalar),\item \( b \) is the bias (a scalar),
- \( \hat{\mathbf{y}} \) is the predicted labels (a scalar row vector),
- \( \mathbf{F} \) is a row vector field (\( \mathbf{F}: \mathbb{R}^{m+1} \to \mathbb{R}^m \)),
- \( F_i \) is the i-th scalar field component of \( \mathbf{F} \),
- \( \mathbf{L} \) is the loss values (a scalar row vector),
- \( \mathbf{G} \) is a row vector field (\( \mathbf{G}: \mathbb{R}^m \to \mathbb{R}^m \)),
- \( G_i \) is the i-th scalar field component of \( \mathbf{G} \),
- \( C \) is the cost (a scalar) and\item \( H \) is a scalar field (\( H: \mathbb{R}^m \to \mathbb{R}^1 \)).
Given fixed \(X \) and \( \mathbf{y} \), the task is to learn some \( \mathbf{w} \) and \( b \) that minimize \( C \). As learning (training the model) progresses, \( \mathbf{w} \), \( b \) and consequently \( \hat{\mathbf{y}} \) change together at each iteration. At the end of each iteration, \( \mathbf{L} \) and \( C \) are computed. While \( \mathbf{L} \) measures the distance between \( \mathbf{y} \) and \( \hat{\mathbf{y}} \) for an example, \( C \) measures the overall loss across all examples. There are several options for \( \mathbf{L} \) like the cross-entropy loss (aka log loss) \( L = G(\mathbf{w}, b) = -y \log(\hat{y}) - (1 - y) \log(1 - \hat{y}) \), for binary classification, while \( C \) is usually the mean over \( \mathbf{L} \), i.e. \(C = H(\mathbf{w}, b) = \frac{1}{m} \sum_{i=1}^m L^{(i)}\). There are also several possibilities for \( \mathbf{F} \) like the linear transformation \( \hat{\mathbf{y}} = \mathbf{F}(\mathbf{w}, b) = \mathbf{w}^T X + b \), as in multiple regression analysis, or the sigmoid function of this transformation \(\hat{\mathbf{y}} = \mathbf{F}(\mathbf{w}, b) = \sigma(\mathbf{w}, b) = \frac{1}{1 + e^{\mathbf{w}^T X + b}}\), as in classification problems. In ANN terminology, \( \mathbf{F} \) is called activation as its job is to excite/activate a neuron.
4 The Gradient Descent Updates for \( \mathbf{w} \) and \( b \)
The gradient descent update rules for the weight vector \( \mathbf{w} \) and bias \( b \) are
\[\ddot{\mathbf{w}} = \dot{\mathbf{w}} - \beta \nabla H(\dot{\mathbf{w}})\]\[\ddot{b} = \dot{b} - \beta \nabla H(\dot{b}),\]
where \( \beta \) is the learning rate and
\[\nabla H(\mathbf{w}) = \left( \frac{\partial H(\mathbf{w})}{\partial w_1}, \dots, \frac{\partial H(\mathbf{w})}{\partial w_n} \right).\]
If \( H(\mathbf{w}) = \frac{1}{m} \sum_{i} L^{(i)} \), then
\[\nabla H(\mathbf{w}) = \frac{1}{m} \left( \sum_{i} \frac{\partial L^{(i)}}{\partial w_1}, \dots, \sum_{i} \frac{\partial L^{(i)}}{\partial w_n} \right).\]
Although the gradient \( \nabla H(\mathbf{w}) \) points in the direction of steepest ascent of \( H \), the subtraction term \( (-\beta \nabla H) \) flips this direction, guiding the parameters toward the minimum of \( H(\mathbf{w}) \), hence the name gradient descent.
Using binary cross-entropy loss \( \mathbf{L} = \mathbf{G}(\mathbf{w}, b) = -\mathbf{y} \log(\mathbf{\hat{y}}) - (1 - \mathbf{y}) \log(1 - \mathbf{\hat{y}}) \), where \( \mathbf{L} \) depends on \( \mathbf{\hat{y}} \) and \( \mathbf{\hat{y}} \) depends on \( \mathbf{w} \), the chain rule gives:
\[\frac{\partial L^{(i)}}{\partial w_j} = \frac{\partial L^{(i)}}{\partial \hat{y}^{(i)}} \cdot \frac{\partial \hat{y}^{(i)}}{\partial w_j} = \frac{\hat{y}^{(i)} - y^{(i)}}{\hat{y}^{(i)} (1 - \hat{y}^{(i)})} \cdot \frac{\partial \hat{y}^{(i)}}{\partial w_j}.\]
Assuming \( \mathbf{\hat{y}} = \mathbf{F}(\mathbf{w}, b) = \sigma(\mathbf{w}^T X + b) \) for binary classification, then:
\[\frac{\partial L^{(i)}}{\partial w_j} = \frac{\hat{y}^{(i)} - y^{(i)}}{\hat{y}^{(i)} (1 - \hat{y}^{(i)})} \cdot \left( x_j^{(i)} \hat{y}^{(i)} (1 - \hat{y}^{(i)}) \right) = (\hat{y}^{(i)} - y^{(i)}) x_j^{(i)}.\]
Substituting into \( \nabla H(\mathbf{w}) \):
\[\nabla H(\mathbf{w}) = \frac{1}{m} \left( \sum x_1^{(i)} (\hat{y}^{(i)} - y^{(i)}), \dots, \sum x_n^{(i)} (\hat{y}^{(i)} - y^{(i)}) \right) = X_{n \times m} (\hat{\mathbf{y}} - \mathbf{y})_{1 \times m}^T.\]
Similarly,
\[\frac{\partial L^{(i)}}{\partial b} = \frac{\hat{y}^{(i)} - y^{(i)}}{\hat{y}^{(i)} (1 - \hat{y}^{(i)})} \cdot \hat{y}^{(i)} (1 - \hat{y}^{(i)}) = \hat{y}^{(i)} - y^{(i)},\]
so
\[\nabla H(b) = \frac{1}{m} \sum (\hat{y}^{(i)} - y^{(i)}).\]
4.1 Why is \( \frac{\partial \hat{y}^{(i)}}{\partial w_j} = \hat{y}^{(i)} (1 - \hat{y}^{(i)}) x_j^{(i)} \)?
Let \( u^{(i)} = \mathbf{w}^T \mathbf{x}^{(i)} + b \). Then
\[\frac{\partial u^{(i)}}{\partial w_j} = x_j^{(i)},\]
since \( \frac{\partial u^{(i)}}{\partial w_j} = \frac{\partial}{\partial w_j} (w_1 x_1^{(i)} + \dots + w_j x_j^{(i)} + \dots + w_n x_n^{(i)} + b) = x_j^{(i)} \).
It is known that \( \frac{\partial \sigma(u^{(i)})}{\partial u^{(i)}} = \sigma(u^{(i)}) (1 - \sigma(u^{(i)})) \). By the chain rule,
\[\frac{\partial \sigma(u^{(i)})}{\partial w_j} = \frac{\partial \sigma(u^{(i)})}{\partial u^{(i)}} \cdot \frac{\partial u^{(i)}}{\partial w_j} = \sigma(u^{(i)}) (1 - \sigma(u^{(i)})) \cdot x_j^{(i)} = x_j^{(i)} \hat{y}^{(i)} (1 - \hat{y}^{(i)}).\]
Similarly, \( \frac{\partial \sigma(u^{(i)})}{\partial b} = \hat{y}^{(i)} (1 - \hat{y}^{(i)}) \).
Note that in this context, \( u^{(i)} \) and \( \hat{y}^{(i)} \) are not scalars but represent independent and dependent variables, respectively, analogous to \( x \) and \( y \) in \( y = f(x) = \sin(x) \).
4.2 Alternative Way of Computing \( \nabla H(w) \) and \( \nabla H(b) \) Using Jacobians
1) Jacobian \( \frac{\partial \mathbf{L}}{\partial \hat{\mathbf{y}}} \)
Since each \( L^{(i)} \) depends only on \( \hat{y}^{(i)} \),
\[\frac{\partial \mathbf{L}}{\partial \hat{\mathbf{y}}} = \begin{bmatrix}\frac{\hat{y}^{(1)} - y^{(1)}}{\hat{y}^{(1)} (1 - \hat{y}^{(1)})} & 0 & \cdots & 0 \\0 & \frac{\hat{y}^{(2)} - y^{(2)}}{\hat{y}^{(2)} (1 - \hat{y}^{(2)})} & \cdots & 0 \\\vdots & \vdots & \ddots & \vdots \\0 & 0 & \cdots & \frac{\hat{y}^{(m)} - y^{(m)}}{\hat{y}^{(m)} (1 - \hat{y}^{(m)})}\end{bmatrix}_{m \times m} = \text{diag} \left( \frac{\hat{\mathbf{y}} - \mathbf{y}}{\hat{\mathbf{y}} \odot (1 - \hat{\mathbf{y}})} \right),\]
where \( \odot \) is elementwise product.
2) Jacobian \( \frac{\partial \hat{\mathbf{y}}}{\partial \mathbf{w}} \)
Using \( \sigma'(u) = \sigma(u)(1 - \sigma(u)) \), for feature \( j \) and example \( i \),
\[\frac{\partial \hat{y}^{(i)}}{\partial w_j} = \hat{y}^{(i)} (1 - \hat{y}^{(i)}) x_j^{(i)}.\]
Thus,
\[\frac{\partial \hat{\mathbf{y}}}{\partial \mathbf{w}} = \begin{bmatrix}\hat{y}^{(1)} (1 - \hat{y}^{(1)}) x_1^{(1)} & \cdots & \hat{y}^{(1)} (1 - \hat{y}^{(1)}) x_n^{(1)} \\\vdots & \ddots & \vdots \\\hat{y}^{(m)} (1 - \hat{y}^{(m)}) x_1^{(m)} & \cdots & \hat{y}^{(m)} (1 - \hat{y}^{(m)}) x_n^{(m)}\end{bmatrix}_{m \times n} = \text{diag} \left( \hat{\mathbf{y}} \odot (1 - \hat{\mathbf{y}}) \right) X^\top.\]
For the bias,
\[\frac{\partial \hat{\mathbf{y}}}{\partial b} = \begin{bmatrix}\hat{y}^{(1)} (1 - \hat{y}^{(1)}) \\\vdots \\\hat{y}^{(m)} (1 - \hat{y}^{(m)})\end{bmatrix}_{m \times 1}.\]
3) Chain Rule to Get \( \frac{\partial \mathbf{L}}{\partial \mathbf{w}} \) and \( \frac{\partial \mathbf{L}}{\partial b} \)
Multiply the Jacobians:
\[\frac{\partial \mathbf{L}}{\partial \mathbf{w}} = \frac{\partial \mathbf{L}}{\partial \hat{\mathbf{y}}} \cdot \frac{\partial \hat{\mathbf{y}}}{\partial \mathbf{w}} = \text{diag} \left( \frac{\hat{\mathbf{y}} - \mathbf{y}}{\hat{\mathbf{y}} \odot (1 - \hat{\mathbf{y}})} \right) \times \text{diag} \left( \hat{\mathbf{y}} \odot (1 - \hat{\mathbf{y}}) \right) X^\top = \text{diag} \left( \hat{\mathbf{y}} - \mathbf{y} \right) X^\top.\]
Explicitly (rows \( i \), columns \( j \)):
\[\frac{\partial \mathbf{L}}{\partial \mathbf{w}} = \begin{bmatrix}(\hat{y}^{(1)} - y^{(1)}) x_1^{(1)} & \cdots & (\hat{y}^{(1)} - y^{(1)}) x_n^{(1)} \\\vdots & \ddots & \vdots \\(\hat{y}^{(m)} - y^{(m)}) x_1^{(m)} & \cdots & (\hat{y}^{(m)} - y^{(m)}) x_n^{(m)}\end{bmatrix}_{m \times n}.\]
For the bias:\[\frac{\partial \mathbf{L}}{\partial b} = \frac{\partial \mathbf{L}}{\partial \hat{\mathbf{y}}} \cdot \frac{\partial \hat{\mathbf{y}}}{\partial b} = \text{diag} \left( \frac{\hat{\mathbf{y}} - \mathbf{y}}{\hat{\mathbf{y}} (1 - \hat{\mathbf{y}})} \right) \times \begin{bmatrix}\hat{y}^{(1)} (1 - \hat{y}^{(1)}) \\\vdots \\\hat{y}^{(m)} (1 - \hat{y}^{(m)})\end{bmatrix} = \begin{bmatrix}\hat{y}^{(1)} - y^{(1)} \\\vdots \\\hat{y}^{(m)} - y^{(m)}\end{bmatrix}_{m \times 1}.\]
4) From \( \frac{\partial \mathbf{L}}{\partial \mathbf{w}} \) to \( \nabla H(\mathbf{w}) \) (Column-Sums View)
By definition,
\[\nabla H(\mathbf{w}) = \left( \frac{\partial H}{\partial w_1}, \dots, \frac{\partial H}{\partial w_n} \right) = \frac{1}{m} \left( \sum_{i=1}^m \frac{\partial L^{(i)}}{\partial w_1}, \dots, \sum_{i=1}^m \frac{\partial L^{(i)}}{\partial w_n} \right).\]
Hence each component of \( \nabla H(\mathbf{w}) \) is the sum of a column of \( \frac{\partial \mathbf{L}}{\partial \mathbf{w}} \) (scaled by \( \frac{1}{m} \)):
\[\frac{\partial H}{\partial w_j} = \frac{1}{m} \sum_{i=1}^m \left( \hat{y}^{(i)} - y^{(i)} \right) x_j^{(i)}.\]
Componentwise vector:
\[\nabla H(\mathbf{w}) = \frac{1}{m} \left( \sum_i x_1^{(i)} (\hat{y}^{(i)} - y^{(i)}), \dots, \sum_i x_n^{(i)} (\hat{y}^{(i)} - y^{(i)}) \right).\]
Compact matrix form:
\[\nabla H(\mathbf{w}) = \frac{1}{m} X_{n \times m} (\hat{\mathbf{y}} - \mathbf{y})_{1 \times m}^\top.\]
5) Gradient w.r.t. Bias \( b \)
Averaging \( \frac{\partial \mathbf{L}}{\partial b} \) over \( m \) examples gives:
\[\nabla H(b) = \frac{\partial H}{\partial b} = \frac{1}{m} \sum_{i=1}^m \left( \hat{y}^{(i)} - y^{(i)} \right),\]
or, in vector form,\[\nabla H(b) = \frac{1}{m} \mathbf{1}_{1 \times m} (\hat{\mathbf{y}} - \mathbf{y})_{1 \times m}^\top.\]